Today is Data Methodology Saturday! Here, we will talk a bit about the Data Methodology, after we will learn what is CRISP-DM. At the last part, I will show you my idea project for CRISP-DM.
Data Science Methodology
This methodology is kind of a light that illuminates the way to solve complex data problems. It like a circuit that starts from Business Understanding, ‘finishes’ in Feedback. See the Image 1.
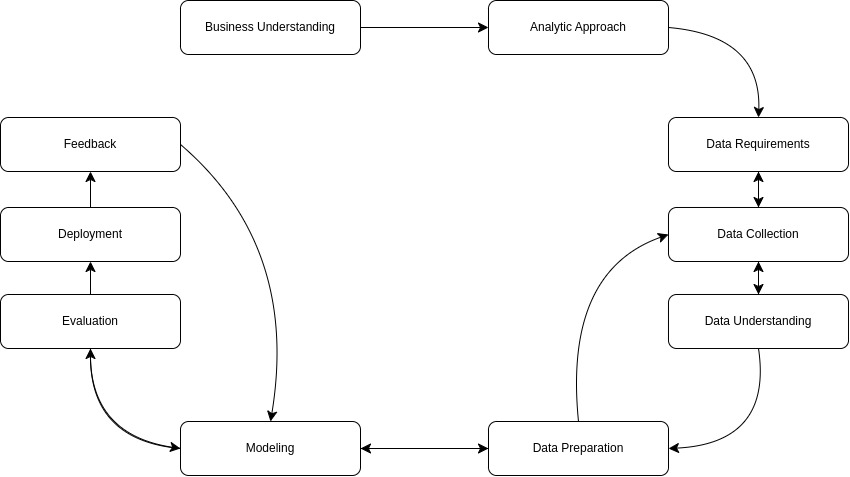
As you can see here, the process starts in Business Understanding, with finding true question, after that finding the best Analytic Approach is the second step. These are followed by data steps until we create our model. At the last part, we evaluate our model, deploy it, and improve our model with the feedbacks.
- Business Understanding: Firstly we need to know what the problem is. For example, if we miss the last session of our class that has an exam next week, it might be a big problem. Here, the most important part is finding the best question. For example: How can I find the important topics for my exam? This question will help us for this situation.
- Analytic Approach: Choosing of the best approach based on our problem is important. But before our selection, we need to understand our question clearly. For example, let’s think about an question that will be answered/classified as yes or no. We can use a decision tree classifier for this example. So, our analytic approach will be decision tree classifier.
- Data Requirements: It is a decision step for what kind of data we need. The first rule of playing with data is to make a choice that will bring you requirements -like that instance: we need scissors to cut a paper.
- Data Collection: Review of the data we have. Taking all of the data we decided might be expensive sometimes. Also it might be hard to collect some data. That’s why, we can postpone or discard these data for later.
- Data Understanding: This is the part where we will check whether the collected data represents the problem at hand. If you can say “yes, it represents the problem well”, so you successfully achieved your data understanding.
- Data Preparation: With data collection and data understanding steps, data preparation is the most time consuming step for a project. When you take notes for an exam, you can fit everything on one page or write it on multiple pages. Both of them will be helpful for you, but if you write just one paper, during the exam it will be better for you. From this point of view, you are done with this step if you think everything is properly prepared for your study.
- Modeling: Developing a descriptive or predictive model step. For example, answer of a predictive model will be yes/no, stop/go, etc.
- Evaluation: To understand the quality of the model, we must evaluate it. If we can get the answer of our business understanding question, we are completed this step.
- Deployment: With this step, we understand what the model can do in the market. At the same time, we will have the chance to make a comparison with the other models.
- Feedback: We improve our model in a forward-looking manner with the user/customer feedback we receive.
These were the 10 stages of the data methodology. These stages follow each other in a cycle. Now we will start talking about CRISP-DM.
What is CRISP-DM?
CRISP-DM (Cross Industry Standard Process for Data Mining) is kind of a base model of data science process. The CRISP-DM consists of 6 cyclical phases that emphasize framing the data science problem from a business perspective upfront, while the data science methodology we talked about provides a more granular, linear breakdown of the process with specific steps for customer handoff and model monitoring.
As we mentioned before, we have just six steps here:
- Business Understanding: Creation of the business question.
- Data Understanding: Finding the required data.
- Data Preparation: Organizing the data for modeling.
- Modeling: Selection of the model technique.
- Evaluation: Evaluation whether the model works well.
- Deployment: For stakeholders to access the result.
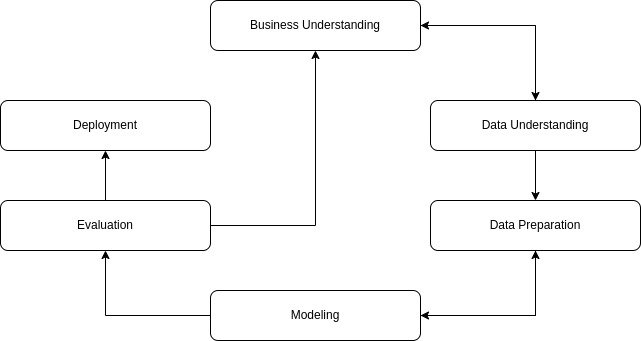
As you can see, we have more less steps in CRISP-DM. In this system, our methodology works a little faster. Additionally, as you can see, there is no feedback section here. Because the principle here is that the feedback constantly improves itself with the stages you see.
My CRISP-DM Project Example (Not real, just my idea)
In today’s digital age, credit card fraud is a persistent threat that can wreak havoc on individuals and businesses alike. As transactions become increasingly cashless and borderless, it’s imperative to have robust systems in place to separate legitimate payments from fraudulent ones. This project will walk you through a real-world example of how to apply the CRISP-DM methodology to tackle this challenge.
- Business Understanding: To develop a predictive model that can accurately distinguish between genuine and fraudulent credit card transactions. This seemingly simple question – “Is this transaction real or fake?” – holds immense value for financial institutions and consumers, as it can help mitigate losses, prevent identity theft, and maintain trust in digital payment systems.
- Analytic Approach: Given the complexity and multitude of factors involved in credit card transactions, a decision tree classifier emerges as a promising analytical approach. By recursively partitioning the data based on various features, decision trees can uncover intricate patterns and rules that separate legitimate transactions from fraudulent ones.
- Data Requirements and Collection: To build an effective predictive model, we’ll need a comprehensive dataset encompassing a wide range of features, including card information, transaction details, geographical locations, customer profiles, security data, biometric identifiers (where available), payment specifics, and system metadata. While most of this data is routinely collected by financial institutions, biometric information may prove challenging to obtain initially.
- Data Understanding and Preparation: Before diving into modeling, it’s crucial to understand the relationships and interdependencies between different data elements. For instance, card information and security data are inherently linked, just as purchase details and geographical locations are intertwined. This understanding will guide our feature engineering and data preparation efforts, ensuring that we extract the most relevant and predictive signals from the raw data.
- Modeling and Evaluation: With our data primed and ready, it’s time to train and evaluate our decision tree classifier. Using a curated subset of features – such as purchase locations, amounts, merchant categories, and transaction systems – our model will classify each transaction as either genuine or fraudulent. We’ll explore alternative modeling techniques and leverage performance metrics like the ROC (Receiver Operating Characteristic) curve to identify the most accurate and robust classification model.
This project I have in mind will perhaps become powerful enough for a bank to use when supported by a strong data set. It is just an idea right now, but who knows, it will be a real project in one day by me. Thank you for reading until here. Have a good weekend!
Bibliography
- “Data Science Methodology and Approach” GeeksforGeeks. March 2024. [https://www.geeksforgeeks.org/data-science-methodology-and-approach/]
- “Data Science CRISP-DM” Data Science PM. March 2024. [https://www.datascience-pm.com/crisp-dm-2/]

Leave a reply to mertkont Cancel reply