
Hello everyone! Today, we will talk about overfitting and how can to avoid our models from it. Let’s start with learning ‘what is overfitting’.
A Turkish proverb says: “Excess of everything is harmful”.
As you can see in the proverb, we do not want to excess of everything. Drinking so much water, eating too much food, sleeping, walking… These are good things, but we should not do them too much.
But what we are going to talk about today is not exactly the same thing. A model can over-learn from a small amount of data. Sometimes, adding new datas can solve that problem.
The problem is our machine learning model in this situation. Without solving it, we will always fail in our test data set.
Let’s define overfitting: it occurs when a machine learning model learns the training data too well, capturing not just the underlying patterns but also the noise and random fluctuations present in the data. This leads to a model that performs exceptionally well on the training set but poorly on unseen data, such as a test.
So, what we learn is overfitting is a high-accuracy problem when working with training data set. We can understand it when we get low-accuracy result on test data set.
Let’s see this overfitting problem on a chart:
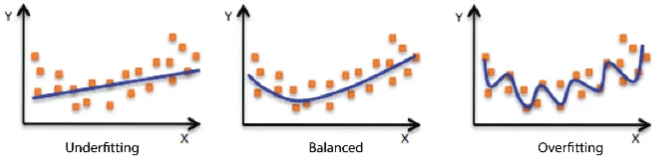
As can be seen in the graph, in the normal (balanced) case, a more linear prediction line is drawn from a place close to the data, while in the overfitting case, a line is drawn very close to the data (another situation, underfitting, which is caused by insufficient learning from the data, is also seen).
It is because of that our model is memorizing. For example, our model memorizes anything, like champions of last 4 seasons (from 2020 to 2024) is Manchester City in Premier League. So, when we ask our model like ‘who will be champion in next season?’, it will answer like ‘Manchester City’, ‘Manchester City’ and ‘Manchester City’.
If we say it in more data scientist way, it causes less MSE (Mean Squared Error), which calculates difference between the real data and predicted data. If we formulate:

- ŷ: Predicted value
- y: Real value
- n: Number of data
So, it is our formula. If our model is overfitted, predicted points -which are y hats- will be closer to real y values. It means that, our model memorized real y points. In our test data set, the model will predict wrong y hat values -from here we will see that we trained a faulty model.
As you can see, this is kind of a problem that we do not want to encounter. It need to be fixed. In this point, I will show you some fixes (click names to access the related post in my blog):
- Increasing data diversity and using more data: If we use more data those are different from elder ones, it will reduce risk of overfitting. Here, we can use Generative AI for new datas -which called data augmentation.
- Feature selection and dimensional reduction: We can find the most important features of our data from their correlation with the y-value. Also, dimensional reduction is one type of solution.
- Changing the parameters: Sometimes, playing with parameters can be useful to solve the overfitting problem. Parameter types vary depending on the model being trained.
- Regularization techniques: There are a few regularization types called L1 (Lasso) and L2 (Ridge) regularization. These techniques addes a penalty to our model’s loss function. It also reduces overfitting risk.
- Ensemble methods: Ensemble methods (Random Forest, AdaBoost, etc.) average a large number of models and offer a solution to the overfitting problem.
- Cross validation: Techniques like K-fold cross-validation help you evaluate how the model performs on different subsets of data.
- Early stopping: If we stop learning of model in a point where validation error is increasing, it will reduce risk of overfitting (also I learned this technique today 😇 ).
That is how we can avoid this problem. That’s all I wanted to say about overfitting. Maybe as an additional information we can mention that Decision Trees can cause too much overfitting, and we can solve this with Ensemble methods that use Decision Trees as a base.
Thus, we have examined the overfitting issue, which is a problem of overlearning and causes us to draw incorrect predictions from the data. We have discussed various methods such as data augmentation, regularization, and ensemble techniques that can be a solution to this problem. Thus, we have reached the end of this blog post.
So, that is all I wanted to say today. Thank you for reading until now. Have a good week!
Bibliography
Medium. Overfitting, balanced and underfitting graph. Date: 11 August 2024, https://medium.com/swlh/overfitting-vs-underfitting-d742b4ffac57

Leave a comment